Redux理解和应用
写在前面:说到redux就不得不说react,之前做过一个项目是纯用react的,所有的数据都使用props和state来管理。无赖后来没有等到项目引进redux就终止了。那时候觉得没有使用redux,react也能自己很好的管理自己的数据,组件之间的通信仅仅是通过props或者回调函数来完成(组件之间的通信参看https://www.javascriptstuff.com/component-communication/)。后来另一个项目中使用了redux,感觉如果当初的业务在复杂一些,比如组件中很多3层组件的情况,并且这些组件之间有复杂的通信,那么单单使用react可能就比较吃力了。
Redux解决了什么问题
redux是一种解决方案。react只是 DOM 的一个抽象层,并不是 Web 应用的完整解决方案。redux并不是必须要用的。但是当组件之间涉及到下面的场景,就需要引入redux。
- 某个组件的状态,需要共享
- 某个状态需要在任何地方都可以拿到
- 一个组件需要改变全局状态
- 一个组件需要改变另一个组件的状态
发生上面情况时,如果不使用 Redux 或者其他状态管理工具,不按照一定规律处理状态的读写,代码很快就会变成一团乱麻。你需要一种机制,可以在同一个地方查询状态、改变状态、传播状态的变化。
设计理念
在接触mvvm的框架的时候会有一些感觉,我们是通过改变数据来改变视图的,因为mvvm框架通常是双向绑定的。react是单向数据流,我们也可以通过某种手段使得同样的数据对应同样的视图。redux的设计理念就是,所有的数据都由store来管理。所有的变动都由action来发起。当view层发起一个action以后,最后由reducers来执行,reducers是一个纯函数,也就是说,只要是同样的输入,必定得到同样的输出。经过reducer处理返回新的state更新到store中。这样的流程使得所有的数据更新都要通过这个流程。
可以理解为一个所有的组件都共用一个store,这样,第一小节中提到的:组件的状态,需要共享;某个状态需要在任何地方都可以拿到;一个组件需要改变全局状态;一个组件需要改变另一个组件的状态等组件之间的通行或者跨页面之间的共享问题就得到解决。
有了redux的规范,项目的文件也会更加清晰,同时也提升了开发体验
Redux工作流程
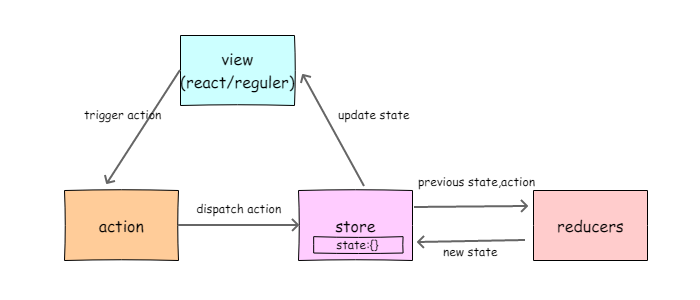
整个工作流程是,view层触发action,store更具action找到对应的reducer,并将当前state和action传给reducer,reducer处理完数据以后返回新的state,view层根据新的state更新视图。
基本概念
Store
Store 就是保存数据的一个对象,一个容器。整个应用有一个 Store。
Redux 提供createStore这个函数,用来生成 Store。
1 | import { createStore } from 'redux'; |
参数reducer是个function如下,传入两个参数,一个是初始State,一个是action
1 | const reducer= (state = initialState, action) => state; |
最终,store是一个类似这样的对象:
1 | const store = { |
这个对象返回三个方法,dispatch,subscribe和getState,dispatch触发以后会修改state,getState会返回当前的state。
store.dispatch()
view想要更新数据state的唯一方法。
1 | store.dispatch({ |
dispatch接受的参数是action。当view层调用dispatch以后,store会根据type: types.LIST的值来判断调用那个一个具体的Reducer。这一步store怎么知道有哪些Reducers是可以搜索的呢,其实是因为,所有的Reducers都经过createStore()处理。具体的细节我还会再写一篇关于原理的笔记。
1 | var store = createStore(Reducers); |
store.subscribe()
添加监听函数,这些函数会在每次dispatch action的时候调用,比如react就是把render()加入监听函数列表,这样每次dispatch action都会触发render(),重新渲染页面。
store.getState()
返回当前的state
state
Store对象包含所有数据。如果想得到某个时刻的数据,就要对 Store 生成快照。这种快照,就叫做 State。
当前时刻的 State,可以通过store.getState()拿到。State也是一个对象。一个State对应一个view,所以相同的State就会有相同的view。有一种说法,可以理解为state是数据流,随着时间移动,某部分state的数据会改变,而view就是state改变的体现。就像是ps中,你的每个操作都会生成一个历史记录,操作前是上一个state的快照,操作后是当前state快照,你的操作就是action。
action
action是唯一可以改变state的方法。state的改变会导致view层的改变。redux的设计就是希望所有对state的修改都只能通过action来触发。所以action是view层想要改变的唯一方法。action是一个对象,其中type是必须的,表示触发哪个action。
1 | { |
###
Reducer
首先,reducer是一个方法,这个方法可以接受两个参数,一个是当前的state,一个是触发的action。
reducer就是最后定义新state返回的函数,这个函数会根据不同的action,返回新的state。随着state的更新,view就也发生了更新。
1 | const reducerA = function (state, action) { |
reducer有个非常重要的属性,就是它是一个纯函数。纯函数只用表达式不用语句,可以保证相同的输入,必定得到同样的输出,并且不修改原来的state,只是反回新的state。redux会根据新旧state的引用地址否相同来判断是否更新state。
进阶
看了上面的基本概念,在看工作流程的那张图,感觉好像明白了一些,接下来,看看实际中,怎么运用。
看看图中大致的流程,view层可以触发很多action,这些action可以按照时间顺序修改store中的state,state改变就可以触发view改变。
第一步 生成reducers
最直观的想,第一步是view层触发action,而文档中说明只有store.dispatch()触发action,所以,store是所有的根本。怎么生成store?
前面说过,只需要引入redux,调用 createStore方法,传入reducers。
reducer是一个方法,如reducer一节例子那样。但是如何项目有无数action,那么就会有无数的case来处理,这样的话,reducer可能有上千行,导致代码很难维护。所有我们需要将reducer按照功能模块进行拆分。
假如把reducer一节例子分成两个功能模块:A 和B。
那么reducerA是这样:
1 | return function (state, action) { |
reducerB是这样:
1 | return function (state, action) { |
然后把两个reducer用combineReducers 组合起来。
combineReducers 辅助函数的作用是,把一个由多个不同 reducer 函数作为 value 的 object,合并成一个最终的 reducers 函数,然后就可以对这个 reducers调用 createStore 方法。
1 | import { combineReducers } from 'redux'; |
也可以直接这样:
1 | import { combineReducers } from 'redux'; |
两种区别是上面一种可以重新命名state的变量名,下面这种默认state中变量名和reducer同名。
合并后的 reducers 可以调用各个子 reducer,并把它们返回的结果合并成一个 state 对象。 由 combineReducers() 返回的 state 对象,会将传入的每个 reducer 返回的 state 按其传递给 combineReducers() 时对应的 key 进行命名。
所以上面的例子对应的state就是下面这样:
1 | { reducerA, reducerB } |
这样,我们就把一个大的reducer拆分成两个模块,并且在state中分别对应不同的变量。实际的项目中可能拆成很多模块,每个模块自己维护自己在state中的变量。
第二步 生成store
上面说了这么多就是为了能给createStore 方法造一个参数,reducers终于参数造好了。
1 | import { createStore } from 'redux'; |
有了store,就可以使用store的三个方法,dispatch,subscribe和getState。
第三步 dispatch action
看起来好像是这样的
1 | store.dispatch({ |
然鹅,实际的运用中,根本不是这样。
实际的action并不是写成{ type: ‘ADD_TODO’, payload: ‘Learn Redux’}这样,而是
1 | export const getList = (data, params) => { |
通过一个方法来返回这个action。
这样做的目的是,可以调用bindActionCreators 方法,该方法的返回值是一个对象,可以通过对象的值直接调用dispatch(action)(隐式调用)。所以在实际的运用中并没有到处都是store.dispatch()。
1 | import * as actions from '../actions'; |
这时候只要使用action.getList()就可以触发action。
1 | action.getList() |
补充
reducer为什么必须是纯函数?
首先纯函数只用表达式不用语句,可以保证相同的输入,必定得到同样的输出。
redux的store中数据是随着时间不断变化的,如果所有的reducer都是纯函数,那么state的每一步变化都,可以用前一个state和后一个state进行还原,有利于测试。
再次,纯函数不修改外部变量,只依赖入参,每次执行action以后,不修改原来的state,只是反回新的state。
为什么这么做?来看看combineReducers方法中的源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var hasChanged = false
var nextState = {}
// 遍历所有的key和reducer,分别将reducer对应的key所代表的state,代入到reducer中进行函数调用
for (var i = 0; i < finalReducerKeys.length; i++) {
var key = finalReducerKeys[i]
var reducer = finalReducers[key]
// 这也就是为什么说combineReducers黑魔法--要求传入的Object参数中,reducer function的名称和要和state同名的原因
var previousStateForKey = state[key]
var nextStateForKey = reducer(previousStateForKey, action)
// 如果reducer返回undefined则抛出错误
if (typeof nextStateForKey === 'undefined') {
var errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
// 将reducer返回的值填入nextState
nextState[key] = nextStateForKey
// 如果任一state有更新则hasChanged为true
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state看倒数第二行
hasChanged = hasChanged || nextStateForKey !== previousStateForKey最终判断是不是发生变化返回的是nextStateForKey !== previousStateForKey,也就是说比较的是两个state的引用是不是同一个。如果reducer返回不是一个新的state,那么这里的引用是同一个,就不会更新store。在js中的对象有两种比较,一种是简单的引用比较,就是比较两个值的的引用地址是不是同一个,浅比较;还有一种比较两个js对象所有的属性是否相同也叫深比较。深比较由于需要层层循环对象来比较,对比的次数很多,开销非常大。
reducer这里正好利用了纯函数的优点,每个reducer最后都返回一个新对象,这样可以用过简单的引用比较(!==)判断是否更新,节约了代码运行成本。可以说是设计的精髓所在。
纯函数式编程优缺点
上面说到了纯函数,不由得让人想起纯函数编程。
什么是纯函数编程
我的理解,纯函数编程 是一种编程规范,就像面向对象编程 一样。主要思路是把运算过程尽量写成一系列嵌套的函数调用。
有什么特点
- 函数只是普通对象 函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
- 只用”表达式”,不用”语句” 不做赋值的操作
- 没有”副作用” 由于纯函数只依赖输入的参数,所以只要相同的输入一定能得到相同的结果
- 不修改状态 函数式编程只是返回新的值,不修改系统变量。
这样就可以得出纯函数基本的原则:
- 不得改写参数
- 不能调用系统 I/O 的API
- 不能调用
Date.now()或者Math.random()等不纯的方法,因为每次会得到不一样的结果
有什么优点
- 代码简洁,开发快速 函数式编程进而可以写成链式,代码简介
- 易于”并发编程” 由于代码的执行只和输入的参数有关,和先后顺序无关,所以没有锁等问题
- 代码的热升级
- 易于测试 只要给出同样的输入,就一定会得到相同结果,易于功能测试
具体还可以参看这篇文章:http://www.ruanyifeng.com/blog/2012/04/functional_programming.html
有什么缺点
代码很难读懂,入门困难
很多地方使用了递归,导致函数式语言的运行速度比较慢
方法不能继承,即使很相似的方法也得重新编写。
面向对象编程的优点“封装”“继承”“多态”就是纯函数编程的缺点。